長崎大学工学部 情報工学コース
平成27年度後期: データ構造とアルゴリズム (水曜日2校時)
平成27年度後期: データ構造とアルゴリズム (水曜日2校時)
追加資料
> シーケンス・データ・マイニングの初歩
- シーケンス・データ (sequence data) とは、ここでは、ひとつの列をなしているデータのことをいいます。
- 音声データ、動画データ、株価、手書き文字データ、遺伝子、たんぱく質、地震計の出力など。
- シーケンス・データを構成する個々のデータを,それぞれひとつの文字で代表させることができれば,
シーケンス・データを,文字列として扱うことができます.
- 実数の列を,文字列として扱うには,どうすればいいでしょうか?
- 100次元ベクトルの列を,文字列として扱うには,どうすればいいでしょうか?
- 以下では,シーケンス・データを文字列として扱います.
そして,長い長い文字列の中から、特定の短い文字列(パターン)を探し出す方法について,
次の2種類に分けて,解説します。
- パターンと完全に一致する部分列を探し出す方法
- パターンと非常に良く一致する部分列を探し出す方法 (完全に一致しなくてもよい)
- この問題を,効率よく解くことは,遺伝情報の分析において,非常に重要です.
- Bowtie ・・・ 最新の方法のひとつ.
> 完全に一致する部分列を探す方法 ~ 力ずく法 (brute-force method)
- 完全に一致すると確認できるまで、パターンを一文字ずつずらしつつ,マッチングをとります。
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCAAG x(1文字の比較でダメと分かったので,1文字分右にずらして,次。)
↓
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCAAG ooox(4文字の比較でダメと分かったので,1文字分右にずらして,次。)
↓
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCAAG ox(2文字の比較でダメと分かったので,1文字分右にずらして,次。)
↓
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCAAG x(1文字の比較でダメと分かったので,1文字分右にずらして,次。)
↓
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCAAG ooooo(見つかった!!!)
- この方法は,見かけほど効率は悪くありません。
- 文字の種類が c 種類で、文字列やパターンが、完全にランダムにつくられているならば、
各回でチェックしないといけない文字数の平均値は
1 + 1/c + (1/c)^2 + ・・・ = c/(c-1)で、定数!
- 何よりも、実装が簡単です.とりあえず文字列探索を試したい場合は、この方法で十分でしょう。
> 完全に一致する部分列を探す方法 ~ BMH(Boyer-Moore-Horspool)法
- BMH法では,パターンを長い文字列と比較するとき,パターンの末尾から先頭へ,文字の比較を進めます. 力ずく法とは反対の方向です.
- 長い文字列が今の位置でパターンと一致しないと分かったら,力ずく法と同じく,パターンをずらします.
- このとき,一致しないと分かった場所での長い文字列の文字を見て, その文字と同じ文字がパターンにもあれば,その文字の位置で,長い文字列とパターンとを揃えます.
- これによって,場合によっては,パターンを何文字分も一気にずらすことができます.
- 一致しないと分かった場所での長い文字列の文字が、パターンに何回も出てくるならば、 パターンをずらす量は,一番控えめにとります。
- ただし,このBMHを使う場合は,前もって,長い文字列に現れるすべての文字について、 それがパターンの何文字目に現れるかを調べておく必要があります.
- もし,同じ文字が,パターンのいくつかの場所に現れる場合は,一番右, つまり,一番末尾に近い位置を記録しておきます.
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCGGA x(Cで不一致。Cが出てくる一番右の位置まで、一気にずらす。)
↓
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCGGA xo(Aで不一致。Aは、いまチェックした位置より左にはもうないので、パターン全体を一気にずらす。)
↓
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCGGA x(Cで不一致。Cが出てくる一番右の位置まで、一気にずらす。)
↓
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCGGA xo(Cで不一致。Cが出てくる一番右の位置まで、一気にずらす。)
↓
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCGGA xo(Cで不一致。Cが出てくる一番右の位置まで、一気にずらす。)
↓
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCGGA x(Gで不一致。Gが出てくる一番右の位置まで、一気にずらす。)
↓
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCGGA x(Cで不一致。Cが出てくる一番右の位置まで、一気にずらす。)
↓
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCGGA x(Gで不一致。Gが出てくる一番右の位置まで、一気にずらす。)
↓
GCCACCAAGTTCCGCACATGCCGGATAGAAT CCGGA ooooo(見つかった!!!)
> おおよそ一致する部分列を探す方法 ~ 動的計画法
- 完全に一致するのではなく、おおよそ一致する部分列を探す必要がある場合もあります。例えば・・・
- ギャップがあっても良い場合。
- 例.GACとGATCは、Tを読み飛ばすことで一致する、と考えてよい場合。
- 違う文字でも一致してよい場合。
- 例.IGMとIGPは、MとPが類似した対象を指す記号なので一致する、と考えてよい場合。
- ここでは、Needleman-WunschのアルゴリズムとSmith-Watermanのアルゴリズムを紹介します。
- いずれも、動的計画法 (dynamic programming) の一種です。
- 参考: シーケンスアラインメント (Wikipedia)
- Needleman-Wunschのアルゴリズムは、ふたつの文字列の全体を一致させるとすれば、 どの文字とどの文字を対応づければよいか,を求めます。
- Smith-Watermanのアルゴリズムは、ふたつの文字列それぞれの部分列で、良く一致するものを、 いくつも求めます。
- まず、何らかの方法で、「この文字とこの文字とは、どれくらい似ているか」を、スコアで表しておきます。
- スコアを事前に計算しておくかわりに、スコアを計算するための関数を定義しておくのでも構いません。
| 表1.スコア例 (「BLOSUM50」と呼ばれるスコア。) | ||||||||||||||||||||
| A | R | N | D | C | Q | E | G | H | I | L | K | M | F | P | S | T | W | Y | V | |
| A | 5 | -2 | -1 | -2 | -1 | -1 | -1 | 0 | -2 | -1 | -2 | -1 | -1 | -3 | -1 | 1 | 0 | -3 | -2 | 0 |
| R | -2 | 7 | -1 | -2 | -4 | 1 | 0 | -3 | 0 | -4 | -3 | 3 | -2 | -3 | -3 | -1 | -1 | -3 | -1 | -3 |
| N | -1 | -1 | 7 | 2 | -2 | 0 | 0 | 0 | 1 | -3 | -4 | 0 | -2 | -4 | -2 | 1 | 0 | -4 | -2 | -3 |
| D | -2 | -2 | 2 | 8 | -4 | 0 | 2 | -1 | -1 | -4 | -4 | -1 | -4 | -5 | -1 | 0 | -1 | -5 | -3 | -4 |
| C | -1 | -4 | -2 | -4 | 13 | -3 | -3 | -3 | -3 | -2 | -2 | -3 | -2 | -2 | -4 | -1 | -1 | -5 | -3 | -1 |
| Q | -1 | 1 | 0 | 0 | -3 | 7 | 2 | -2 | 1 | -3 | -2 | 2 | 0 | -4 | -1 | 0 | -1 | -1 | -1 | -3 |
| E | -1 | 0 | 0 | 2 | -3 | 2 | 6 | -3 | 0 | -4 | -3 | 1 | -2 | -3 | -1 | -1 | -1 | -3 | -2 | -3 |
| G | 0 | -3 | 0 | -1 | -3 | -2 | -3 | 8 | -2 | -4 | -4 | -2 | -3 | -4 | -2 | 0 | -2 | -3 | -3 | -4 |
| H | -2 | 0 | 1 | -1 | -3 | 1 | 0 | -2 | 10 | -4 | -3 | 0 | -1 | -1 | -2 | -1 | -2 | -3 | 2 | -4 |
| I | -1 | -4 | -3 | -4 | -2 | -3 | -4 | -4 | -4 | 5 | 2 | -3 | 2 | 0 | -3 | -3 | -1 | -3 | -1 | 4 |
| L | -2 | -3 | -4 | -4 | -2 | -2 | -3 | -4 | -3 | 2 | 5 | -3 | 3 | 1 | -4 | -3 | -1 | -2 | -1 | 1 |
| K | -1 | 3 | 0 | -1 | -3 | 2 | 1 | -2 | 0 | -3 | -3 | 6 | -2 | -4 | -1 | 0 | -1 | -3 | -2 | -3 |
| M | -1 | -2 | -2 | -4 | -2 | 0 | -2 | -3 | -1 | 2 | 3 | -2 | 7 | 0 | -3 | -2 | -1 | -1 | 0 | 1 |
| F | -3 | -3 | -4 | -5 | -2 | -4 | -3 | -4 | -1 | 0 | 1 | -4 | 0 | 8 | -4 | -3 | -2 | 1 | 4 | -1 |
| P | -1 | -3 | -2 | -1 | -4 | -1 | -1 | -2 | -2 | -3 | -4 | -1 | -3 | -4 | 10 | -1 | -1 | -4 | -3 | -3 |
| S | 1 | -1 | 1 | 0 | -1 | 0 | -1 | 0 | -1 | -3 | -3 | 0 | -2 | -3 | -1 | 5 | 2 | -4 | -2 | -2 |
| T | 0 | -1 | 0 | -1 | -1 | -1 | -1 | -2 | -2 | -1 | -1 | -1 | -1 | -2 | -1 | 2 | 5 | -3 | -2 | 0 |
| W | -3 | -3 | -4 | -5 | -5 | -1 | -3 | -3 | -3 | -3 | -2 | -3 | -1 | 1 | -4 | -4 | -3 | 15 | 2 | -3 |
| Y | -2 | -1 | -2 | -3 | -3 | -1 | -2 | -3 | 2 | -1 | -1 | -2 | 0 | 4 | -3 | -2 | -2 | 2 | 8 | -1 |
| V | 0 | -3 | -3 | -4 | -1 | -3 | -3 | -4 | -4 | 4 | 1 | -3 | 1 | -1 | -3 | -2 | 0 | -3 | -1 | 5 |
> おおよそ一致する部分列を探す方法 ~ Needleman-Wunschのアルゴリズム
- Needleman-Wunschのアルゴリズムは,二つの文字列が与えられたとき, それら二つの文字列全体を,うまく対応付けようとするときに使うアルゴリズムです.
- Needleman-Wunschのアルゴリズムを使うと,次のような答えが得られます.
- 二つの文字列のあいだで,どの文字とどの文字を対応付けるのが良いか.
- あるいは,どうしても文字と文字の対応付けができないとき, どちらの文字列のどの個所で一文字読みとばす(=ギャップを入れる)のが良いか.
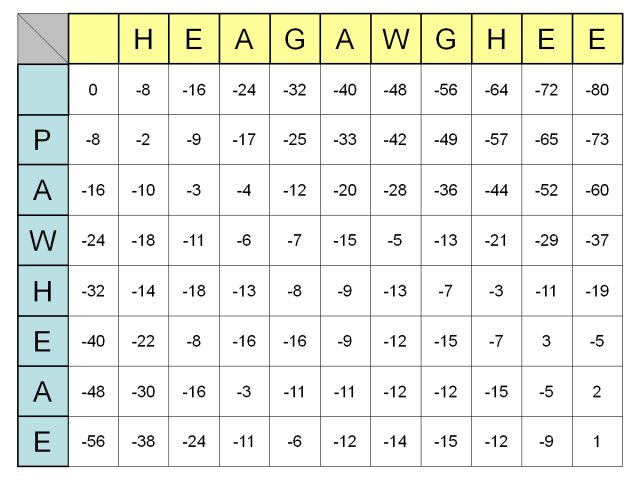
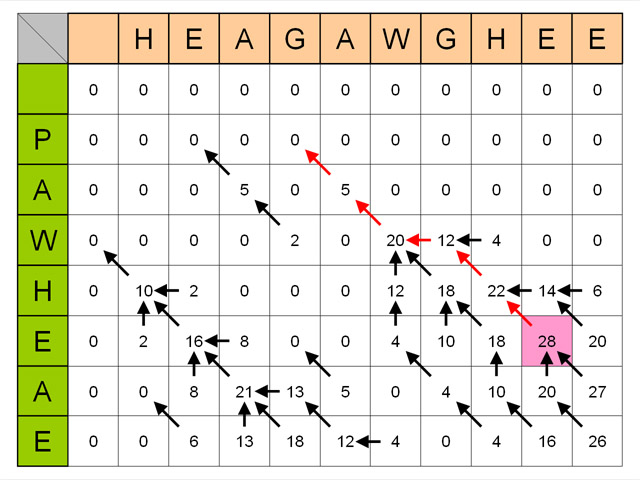
- アルゴリズムを使う前に,次のような,文字列と文字列のマッチングの度合を表現したマトリックスを, 最も左上のマスから始めて,右下のほうへ移動しながら,ひとマスずつ作っていきます.
- このマトリックスの作り方は,以下のとおりです.
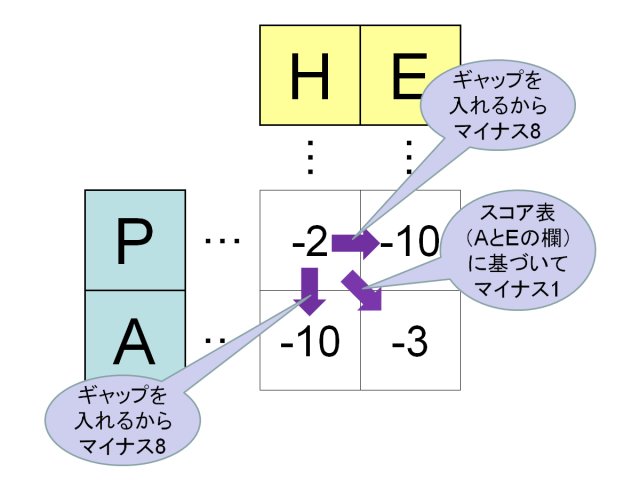
- 右斜め下のマス目に移動するときは,移動先のマス目に対応する文字の組み合わせを, 上に示した表(BLOSUM50のようなスコア表)から探し, その点数を,現在のマス目の点数に加算して,その右斜め下のマス目に記入する.
- 右,または,下のマス目に移動するときは,ギャップ(=一文字読みとばし)が入るという意味なので, マイナス8点のペナルティを課し,その値をマス目に記入する.
- 同じマス目には,3通りの経路(上から,左から,左斜め上から)で到達できるので, そのうち,一番大きな値を,そのマス目のスコアとする.
- マトリックスが完成したら、ふたつの文字列の末尾のマス目からスタートして、 以下のルールに従って,もっとも左上のマス目へと,さかのぼっていきます.
- そのマス目のスコアが,上のマス目からの移動によって計算されたものならば,上のマス目へ.
- そのマス目のスコアが,左のマス目からの移動によって計算されたものならば,上のマス目へ.
- そのマス目のスコアが,左斜め上のマス目からの移動によって計算されたものならば, 左斜め上のマス目へ.
- 上の例では,以下のような対応付けが得られたことになります.(「-」はギャップを意味します.)
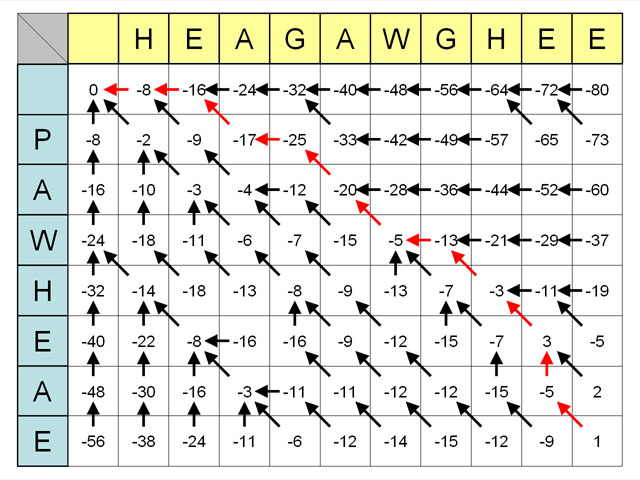
HEAGAWGHE-E・・・横方向(黄色)の文字列 --P-AW-HEAE・・・縦方向(水色)の文字列
> おおよそ一致する部分列を探す方法 ~ Smith-Watermanのアルゴリズム
- Smith-Watermanのアルゴリズムは,二つの文字列が与えられたとき, それら全体を対応付けるのではなく,よく一致する部分列を見つけるために使います.
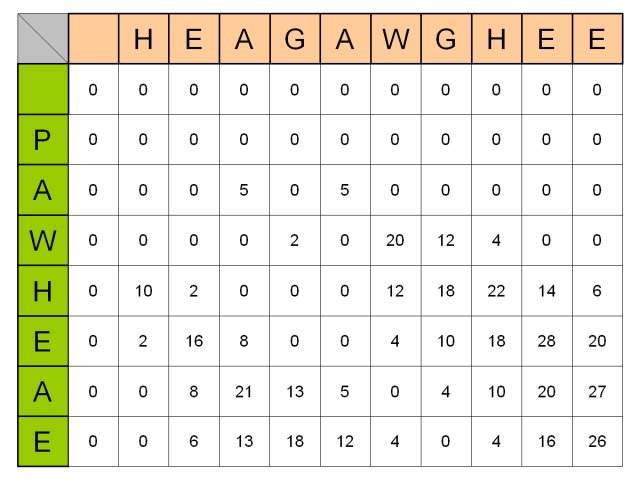
- Smith-Watermanのアルゴリズムでも、Needleman-Wunschのアルゴリズムと同じようにして, 二つの文字列の対応付けのマトリックスを作ります.
- Needleman-Wunschアルゴリズムのスコア表との違いは, スコアが負になったらそのマス目の点数は0にする,という点にあります.
- スコアを負にするくらいなら,部分列の対応付けを一からやり直したほうがいい,という発想です.
- マトリックスが完成したら、最も大きなスコアが現れているマス目からスタートして、 そのマス目のスコアの由来となっているマス目へ、さかのぼっていきます。
- 2番目に大きなスコアが現れているマス目からスタートして、 そのマス目のスコアの由来となっているマス目へとさかのぼれば、また別の答えが得られます。
- このようにして,良く対応する部分列のペアを,いくつか,得ることができます.
[戻る]